Best Practices
Follow these best practices when building fields and templates in CEDAR:
-
Naming Fields

- For the “Field name” label, use snake_case format (e.g.,
parent_dataset_idinstead ofParent Dataset ID). - For the “Preferred Label”, use title case format (e.g.,
Parent Dataset ID).
- For the “Field name” label, use snake_case format (e.g.,
- Creating Descriptions
- Provide clear and concise descriptions for each field.
- Include an example value after the description. For example, the “Parent Dataset ID” field description could be:
Unique identifier of the dataset used to generate this derived dataset. Example: HNDF-123-HH.. - Use ChatGPT or other LLM tools to improve the text quality when writing the description.
-
Naming Boolean Fields
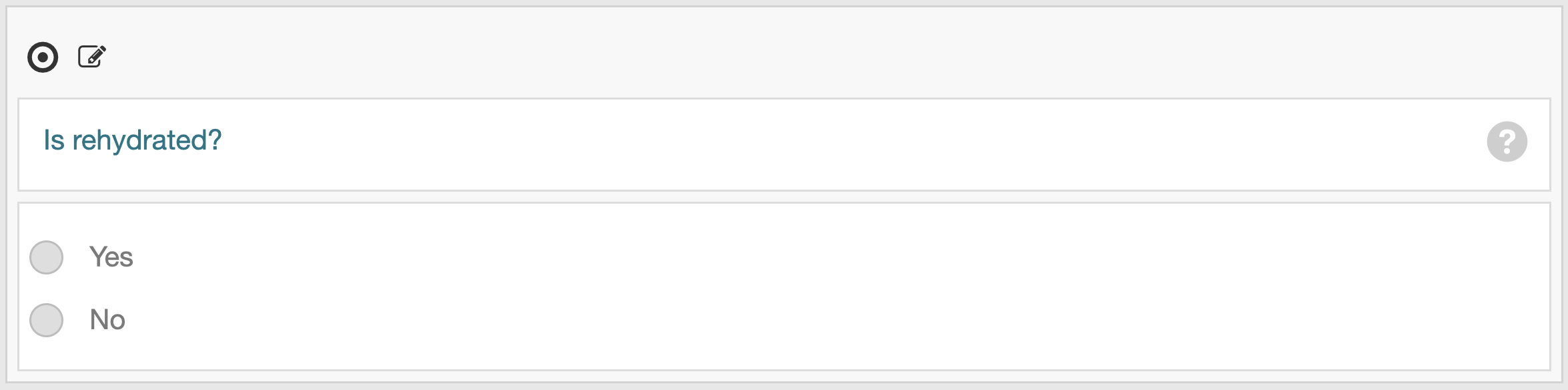
Use a question format for boolean fields (e.g.,
is_rehydrated,is_cell_type_annotation_included) to indicate a “Yes” or “No” response. -
Using Regular Expressions for Identifier Validation
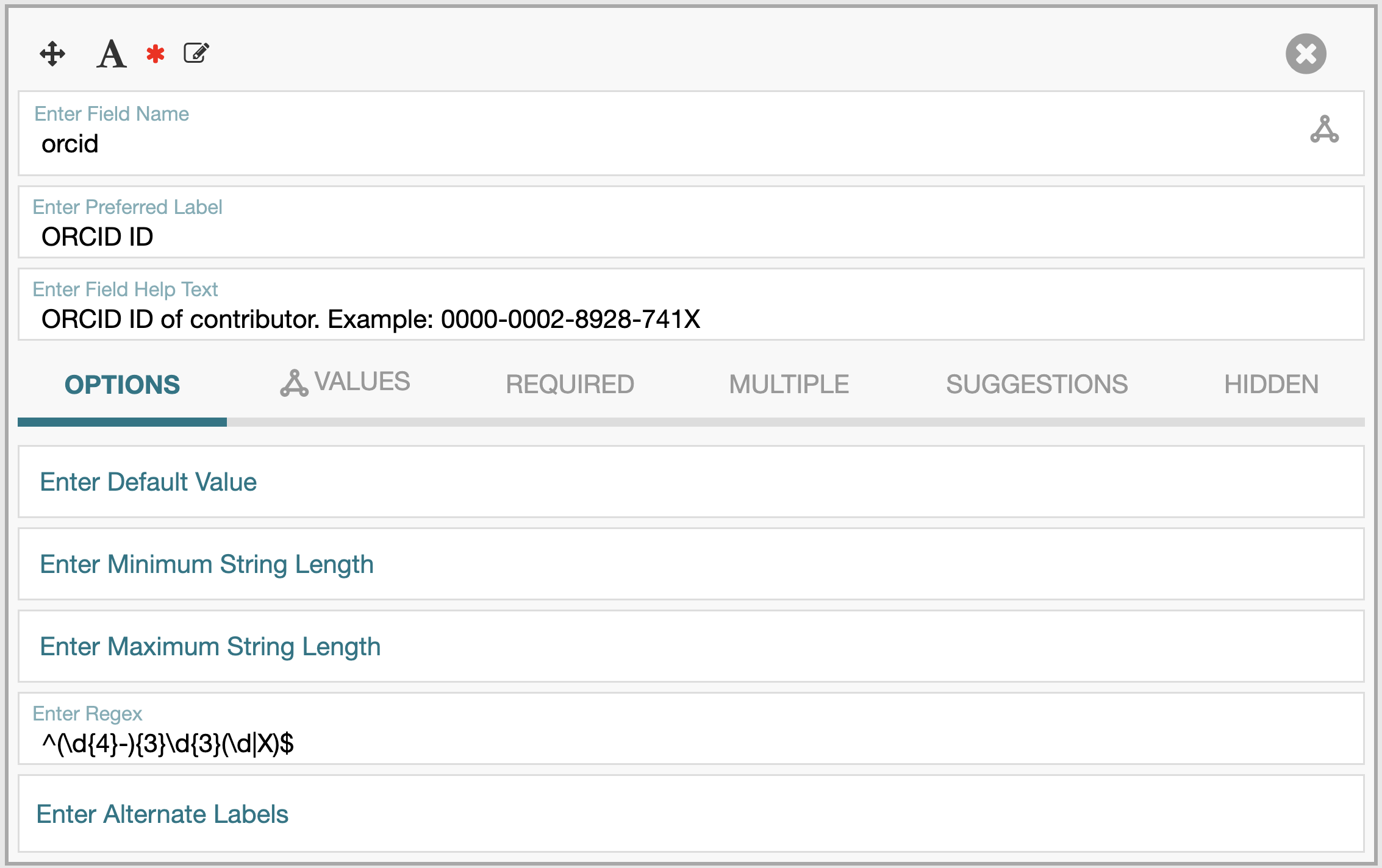
- Apply regular expressions to ensure identifier fields match specific patterns. To do this, select the “OPTIONS” setting and enter the desired regex in the “Enter Regex” field.
- Common regex patterns:
- ORCID:
(\d{4}-){3}\d{3}(\d|X) - DOI:
10\.\d+/.* - UniProt ID:
([A-N,R-Z][0-9]([A-Z][A-Z, 0-9][A-Z, 0-9][0-9]){1,2})|([O,P,Q][0-9][A-Z, 0-9][A-Z, 0-9][A-Z, 0-9][0-9])(\.\d+)?] - ISBN:
(-13|-10)?[:]?[ ]?(\d{2,3}[ -]?)?\d{1,5}[ -]?\d{1,7}[ -]?\d{1,6}[ -]?(\d|X)
- ORCID:
- Tip: Visit Identifiers.org for more regex examples.
- Using Value Set vs. Multiple Choice
- Decide between value sets and multiple choice based on whether the values are shareable concepts. Use Multiple Choice for non-shareable values, such as a collection of input parameters.
Related Topics
- Return to building CEDAR templates page.
- Review the guide on creating reusable fields.